
Štítky ve WordPressu jsou tak trochu peklo. Nejen že je třeba je udržovat tak abyste neměli zbytečné štítky (takové co mají žádné nebo minimum článků), ale velmi snadno vznikají různorodé “duplicity”. Hlavně tak že zadáte štítek jinak, než jste ho dříve zadali. Nebo při zadávání překlepem vznikne jiná forma.
Jednou za čas se vyplatí čistit takto “duplicitní” štítky – zrušit špatný a převést k němu přiřazené články na správnou firmu není až tak problém, v tom vám pomůže TaxoPress plugin. Umí totiž Merge/Rename kdy prostě ukážete na špatný štítek a pak vyberete ten správný a vše přiřazené k špatnému převede na nový.
Problém je, že TaxoPress neumí hledat duplikáty. A nevypadá to, že by existoval plugin, který by to uměl – hlavně s fuzzy logikou, tedy zohledňoval překlepy, chybějící znaky, prohozená slova.
TIP: Jak pracovat se štítky u článků? Kompletní návod jak na štítky u obsahového webu (1) je počáteční díl velmi užitečné série tipů popisující jak pracovat se štítky
Pomůže AI
Vydal jsem se zkoušet Bard se zadáním “I have csv file with strings (tags from wordpress) and i need to find duplicates in them, can you help me?“ a postupnou konverzací jsme došli ke skriptu v Pythonu. Ten si můžete pustit v počítači, nebo v něčem jako Google Colab.
V Pythonu můžete využít knihovnu fuzzywuzzy vhodnou právě k nalézání fuzzy duplikátů. A výsledný kód najdete o kousek níže. Počítá s tím, že na vstupu bude mít v tags.csv export tagů (uložte jako ANSI) a výstup, tedy přehled duplicit uloží do duplicate.csv
import fuzzywuzzy.fuzz as fuzz
import csv
def is_duplicate(tag1, tag2):
if tag1 == tag2:
return False
else:
return fuzz.ratio(tag1, tag2) > 90
def find_duplicates(tags):
duplicates = []
for tag1 in tags:
for tag2 in tags:
if is_duplicate(tag1, tag2):
duplicates.append((tag1, tag2))
return duplicates
# Read the CSV file into a list of tags
tags = []
with open('tags.csv', 'r') as f:
for line in f:
tags.append(line.strip())
# Find non-exact duplicates
duplicates = find_duplicates(tags)
# Save the results to a CSV file
with open('duplicates.csv', 'w', newline='') as f:
writer = csv.writer(f)
for duplicate in duplicates:
writer.writerow(duplicate)
Aby to fungovalo, tak budete potřebovat nainstalovat onu výše zmíněnou knihovnu, tj:
pip install fuzzywuzzy
a vyplatí se nainstalovat i další knihovnu, která vše výrazně zrychlí
pip install python-Levenshtein
Získat štítky z WordPressu
Ještě před tím vším ale musíte z vašeho WordPressu dostat štítky – to jde nejlépe udělat v nějakém tom Admineru či phpMyAdmin kde spustíte SQL dotaz
SELECT name FROM wp_terms WHERE term_id IN (SELECT term_id FROM wp_term_taxonomy WHERE taxonomy = 'post_tag');
Získaný výstup pak pomoci export uložíte do tags.csv – případně pře uložení do ANSI ve Windows snadno v Notepadu – otevřete, dáte Uložit Jako a dole vyberete kódování.
Zpracování je už jen na vás
Výsledek v duplicates.csv si pak můžete otevřít (Excel, Google Sheets, atd) a jít řádku po řádce nalezených duplicit – v TaxoPress pak můžete snadno v Manage Terms -> Merge Terms zvolit nejprve špatnou a poté dobrou formu a nechat spojit. Dost se hodí našeptávač.
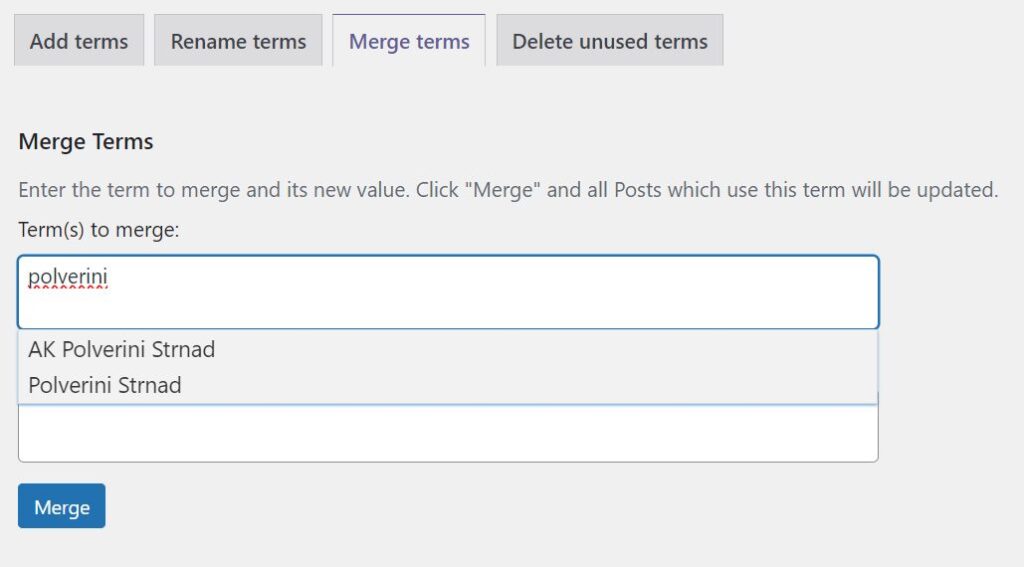
Jak vypadá výstup vidíte níže (z FeedIT.cz). Je dost jisté, že některé z duplicit nezjistí, ale to můžete ovlivnit i volbou fuzz.ratio ve skriptu. Ne vše také musí být duplicity – Adastra a Aastra jsou dva správné štítky. Proto je nutné aby výsledek zpracovával člověk.

Mimochodem, ten zvláštní duplikát na řádku 17/19 kde jsou v názvu otazníky je způsobeny tím, že otazníky jsou ‌ (tzv. zero-width non-joiner) – v tomto konkrétním případě je asi někdo (dost zbytečně) použil v tiskové zprávě a přes copy/paste pak došlo k vytvoření štítku – jde o neviditelné znaky, takže ve WordPressu je neuvidíte.
FeedIT.cz má přes 5 tisíc štítků – výše uvedený skript našel zhruba 200 duplikátů.
Další tipy týkající se WordPressu
-

TIP#1276: Má smysl umístit na web odkazy na aktuální články na (vašich) dalších webech?
Blíží se konec jednoho experimentu co běžel vlastně čtyři roky. Na @feeditcz, @justitcz, @bookzcz, @poohcz jsem při jejich zprovoznění vždy umístil odkazy na aktuální články na ostatní weby. Někde to bylo v…
-
TIP#1235: Jak bezpečně používat WordPress a proč se weby na WordPressu tolik kradou?
Tento tip vlastně platí pro každou online službu, kterou používáte. Tedy alespoň pravidla napsaná na počátku, WordPress je totiž blogovací systém a používáte ho s pomocí účtu co má přihlašovací údaje –…
-

TIP#1211: K čemu je Facebook Debugger (Sharing Debugger) a kde ho najdu?
O Sharing Debuggeru (dříve prostě Facebook Debugger, ještě předtím URL Debuger či URL Linter) už je řeč v Co udělat se špatně vloženým odkazem na Facebooku? Jak ho napravit? a Co dělat když…
-

TIP#1196: Jak na obsahovém webu štítky ukazovat a používat v rámci designu? Kompletní návod jak na štítky u obsahového webu (3)
Máte web s obsahem, vydáváte články (něco jako @365tipů například), ty obsahují štítky. Už jste zvládli proces práce se štítky i čas od času udržujete štítky. Je samozřejmě nutné, abyste štítky také…
-

TIP#1195: Jak udržovat štítky na obsahovém webu? Co vás pravidelně čeká? Kompletní návod jak na štítky u obsahového webu (2)
V prvním díle Jak pracovat se štítky u článků? je hodně detailní postup a pravidla, které určují použití existujících štítků a tvorby nových štítků. Po určité době vás ale vždy čeká revize…
-

TIP#1194: Jak pracovat se štítky u článků? Kompletní návod jak na štítky u obsahového webu (1)
O štítcích tu byla řeč někdy dávno před třemi lety v Štítky (i hashtagy) jsou dobrá cesta k zprostředkování obsahu i dalším věcem. Je to dost obecné, a i když k tomu přidáte…
-

TIP#1176: Je WordPress zadarmo? Budu za něco platit?
Když už před pár dny vzniklo Jak na WordPress pro blogování i vytvoření webu, tak je možná čas postupně trochu zapracovat na dalších tipech právě pro WordPress. Sice nebudou hojně vyhledávané, nezajistí…
-

TIP#1136: Prověřujte čas od času 404 chyby na webu či blogu
Chyba 404 je označení chyby „neexistující URL“, objeví se v okamžiku, kdy si vyžádáte nějakou internetovou adresu, která nevede na existující obsah. Může jít o chybu v URL, ale také obsah, který…
-

TIP#1065: Jak je to s „ochranou“ proti kopírování textu na webových stránkách?
Možná jste se s tím již setkali, jste ně nějakém webu, chcete zkopírovat nějaký text do e-mailu nebo na sociální sítě. A k tomu co jste si označili a důvěřivě kopírujete se…
-

TIP#1000: Jak můžete na vlastní web dostat vyhledávání?
V Jak mohu mít vyhledávání od Google na svém webu? Přes Google Custom Search Engine byla řeč o tom, jak můžete využít služby Google pro doplnění vyhledávání přímo na vlastní webové stránky.…
-
TIP#928: Jak se bránit proti komentářovému spamu na blogu/webu?
Pamatujte si, jakmile kamkoliv na Internet pověsíte možnost vkládat nekontrolovaně obsah, tak dříve nebo později se dostaví „komentářový spam“. Nejprve se vám tam objeví něco ručně zadávaného – reklama, odkazy na zavirované…
-

TIP#855: Mám texty pro blog psát přímo na blogu nebo si je připravovat v počítači (mimo blog)?
Tenhle problém je takový zapeklitý, týkající se toho, že máte nějaký blog (ale obecně, jakýkoliv web na který věšíte texty, články) a tvoříte pro něj obsah. A otázka, zásadní, je, zda ty…
-

TIP#835: Co se stane, když 365tipu.wordpress.com přesunete na 365tipu.cz
Možná jste si už všimli, že @365tipu je už do spuštění (což bylo 1. ledna 2015) jeden velký experiment. Slouží k ověření i zjištění řady věcí. Proto také dlouhou dobu tenhle web…
-

TIP#818: Jak z webu jako je @365tipu automaticky plnit různorodé sociální sítě
Pokud dnes cokoliv vydáváte, ať už je to web, noviny, magazín či blog, tak už nestačí jenom mít k webu RSS a možnost přihlásit se k odběru e-mailem. Dnes je velmi vhodné,…
-

TIP#804: Jak migrovat web z WordPress.org na WordPress.com? Krok 7: Co získáte použitím WordPress.com místo vlastního hostingu
Poněkud delší série mimořádných tipů vychází z toho, že se stěhovalo několik webů (www.justit.cz, www.feedit.cz, www.bookz.cz a www.bradbury.cz) z vlastního WordPressu (na virtuálním privátním serveru, VPS) na WordPress.com. Mezitím se tam ještě…




