
Štítky ve WordPressu jsou tak trochu peklo. Nejen že je třeba je udržovat tak abyste neměli zbytečné štítky (takové co mají žádné nebo minimum článků), ale velmi snadno vznikají různorodé “duplicity”. Hlavně tak že zadáte štítek jinak, než jste ho dříve zadali. Nebo při zadávání překlepem vznikne jiná forma.
Jednou za čas se vyplatí čistit takto “duplicitní” štítky – zrušit špatný a převést k němu přiřazené články na správnou firmu není až tak problém, v tom vám pomůže TaxoPress plugin. Umí totiž Merge/Rename kdy prostě ukážete na špatný štítek a pak vyberete ten správný a vše přiřazené k špatnému převede na nový.
Problém je, že TaxoPress neumí hledat duplikáty. A nevypadá to, že by existoval plugin, který by to uměl – hlavně s fuzzy logikou, tedy zohledňoval překlepy, chybějící znaky, prohozená slova.
TIP: Jak pracovat se štítky u článků? Kompletní návod jak na štítky u obsahového webu (1) je počáteční díl velmi užitečné série tipů popisující jak pracovat se štítky
Pomůže AI
Vydal jsem se zkoušet Bard se zadáním “I have csv file with strings (tags from wordpress) and i need to find duplicates in them, can you help me?“ a postupnou konverzací jsme došli ke skriptu v Pythonu. Ten si můžete pustit v počítači, nebo v něčem jako Google Colab.
V Pythonu můžete využít knihovnu fuzzywuzzy vhodnou právě k nalézání fuzzy duplikátů. A výsledný kód najdete o kousek níže. Počítá s tím, že na vstupu bude mít v tags.csv export tagů (uložte jako ANSI) a výstup, tedy přehled duplicit uloží do duplicate.csv
import fuzzywuzzy.fuzz as fuzz
import csv
def is_duplicate(tag1, tag2):
if tag1 == tag2:
return False
else:
return fuzz.ratio(tag1, tag2) > 90
def find_duplicates(tags):
duplicates = []
for tag1 in tags:
for tag2 in tags:
if is_duplicate(tag1, tag2):
duplicates.append((tag1, tag2))
return duplicates
# Read the CSV file into a list of tags
tags = []
with open('tags.csv', 'r') as f:
for line in f:
tags.append(line.strip())
# Find non-exact duplicates
duplicates = find_duplicates(tags)
# Save the results to a CSV file
with open('duplicates.csv', 'w', newline='') as f:
writer = csv.writer(f)
for duplicate in duplicates:
writer.writerow(duplicate)
Aby to fungovalo, tak budete potřebovat nainstalovat onu výše zmíněnou knihovnu, tj:
pip install fuzzywuzzy
a vyplatí se nainstalovat i další knihovnu, která vše výrazně zrychlí
pip install python-Levenshtein
Získat štítky z WordPressu
Ještě před tím vším ale musíte z vašeho WordPressu dostat štítky – to jde nejlépe udělat v nějakém tom Admineru či phpMyAdmin kde spustíte SQL dotaz
SELECT name FROM wp_terms WHERE term_id IN (SELECT term_id FROM wp_term_taxonomy WHERE taxonomy = 'post_tag');
Získaný výstup pak pomoci export uložíte do tags.csv – případně pře uložení do ANSI ve Windows snadno v Notepadu – otevřete, dáte Uložit Jako a dole vyberete kódování.
Zpracování je už jen na vás
Výsledek v duplicates.csv si pak můžete otevřít (Excel, Google Sheets, atd) a jít řádku po řádce nalezených duplicit – v TaxoPress pak můžete snadno v Manage Terms -> Merge Terms zvolit nejprve špatnou a poté dobrou formu a nechat spojit. Dost se hodí našeptávač.
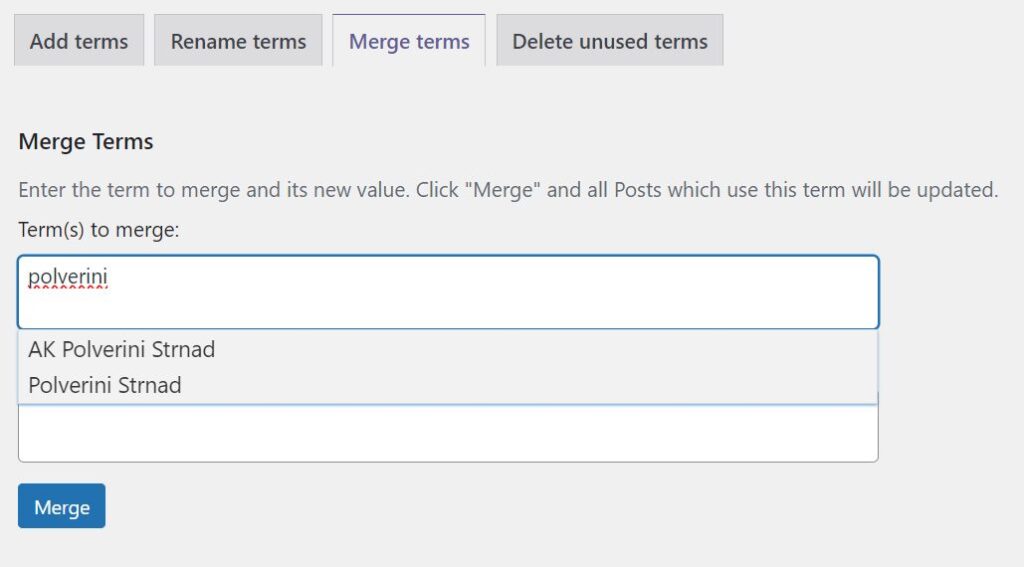
Jak vypadá výstup vidíte níže (z FeedIT.cz). Je dost jisté, že některé z duplicit nezjistí, ale to můžete ovlivnit i volbou fuzz.ratio ve skriptu. Ne vše také musí být duplicity – Adastra a Aastra jsou dva správné štítky. Proto je nutné aby výsledek zpracovával člověk.

Mimochodem, ten zvláštní duplikát na řádku 17/19 kde jsou v názvu otazníky je způsobeny tím, že otazníky jsou ‌ (tzv. zero-width non-joiner) – v tomto konkrétním případě je asi někdo (dost zbytečně) použil v tiskové zprávě a přes copy/paste pak došlo k vytvoření štítku – jde o neviditelné znaky, takže ve WordPressu je neuvidíte.
FeedIT.cz má přes 5 tisíc štítků – výše uvedený skript našel zhruba 200 duplikátů.
Další tipy týkající se WordPressu
-

TIP#053: Celé články nebo jenom upoutávky? Obvyklé dilema u blogu. WordPress na tohle má značku
Když jsem začínal s @365tipu, tak jsem nepředpokládal, že bude větší počet „delších“ textů. Skutečnost je samozřejmě taková, že nakonec těch delších textů je víc. Znamená to, že jsem původně vsadil na…
-

TIP#039: Nejčtenější články, čtenáři je mají rádi a vám pomohou
Statistiky a analýzy není radno podceňovat. Jednou z nich jsou nejčtenější články (v době sociálních sítí i nejsdílenější či nejvíce lajkované). Vy sami se z nich dozvíte, o co byl největší zájem…
-

TIP#035: Je dobré vědět, odkud k vám přicházejí lidé. Co že je to ten referer?
Dnes je to se zjišťováním toho, odkud (a hlavně proč) na váš web přicházejí lidé těžké. Snadné zjištění toho na jaké fráze vás lidé našli v Google je dnes už podstatně problematičtější.…
-

TIP#013: Štítky (i hashtagy) jsou dobrá cesta k zprostředkování obsahu i dalším věcem
Štítky, nálepky, v novější sociální podobě hashtagy jsou užitečná věc. Osobně je pro blogy a obsahové weby velmi v oblibě, dávám jim i přednost před rubrikami. Byť zpravidla pro obsahový web rubriky…
-

TIP#010: Google Analytics na WordPress.com pořídíte jen v placené (od Premium) podobě. Vědět čísla je vždy užitečné
Je sobota, takže jenom krátce a možná ne až tak velmi užitečně jako v některých předchozích tipech. A taky je čas se tak trochu pochlubit tím, jak to vlastně s @365tipu vypadá.…
-

Co všechno by mělo být na blogu aby dobře fungoval pro čtenáře i autora?
Ve WordPressu tyto věci můžete přidávat pomocí předem hotových modulů- Hledejte v nastaveni Widgets/Widgety – jsou k nalezení v části „Vzhled“.
-

Problémy, problémy a jenom problémy. S fonty ….
„Ahoj, v Chrome OS je nějaký problém s písmem, “ napsal Janek Wagner a s ním ještě pár dalších lidí, včetně těch an Twitteru a Facebooku. Jasně, české znaky se v šabloně…
-
365 tipů. Co jeden den, to jeden tip. A spousta věci k vyzkoušení
Ne že bych neměl co dělat, ale prostě občas chcete něco zkusit. Podívat se jak se vyvinuly některé služby. Vidět je tak jak by je viděl někdo, kdo je nikdy nepoužil a…




