
Jedna z velmi častých věcí pro zdejší newsletter, ale i pro #tyden. Shrnout článek odněkud do odstavce textu. Není to až tak triviální, jak by se mohlo zdát
Nahradil jsem DeepL (viz Jak na ChatGPT API pro překlad z a do češtiny) a na klávesové zkratce mám překlad clipboard z/do češtiny (sám pozná kam překládat). A potřeboval jsem ještě souhrn v podobě dvou/tří odstavců. Vlastně tak nějak, jak to (třeba) dělá TechMeme.

V klasické webové/aplikační ChatGPT to můžete udělat snadno, hodíte tam URI článku a řeknete, ať vám udělá zpravodajský souhrn, maximálně 3 věty a případně to ještě trochu omezíte. Má ale tendenci si vymýšlet, na adresu se prostě často vůbec nepodívá a taky je strašně ochotná tím, že tam přidává věci, které tam ani nechcete. Souvislosti a tak. Na řadu adrese se ani nedostane, protože web blokuje přístup pro AI boty.
Přes API to má jednu výhodu, udělá jen to co po ní chcete ale na Internet stejně nemůže jít. Ten článek jí totiž musíte dovat vy jako součást zadání (promptu).
Je a to trochu dražší než obyčejný překlad, protože na vstupu budete mít článek – stovky až tisíce znaků a je s tím spojených pár zádrhelů.
- článek bude stahovat váš Python a často narazí na to, že ho médium stejně zablokuje jako robota
- z URL nemůžete poslat do ChatGPT všechno, jde vám jenom o článek jako takový, ne to smetí okolo
- moc dlouhé články je praktické poslat do ChatGPT postupně
ChatGPT má každopádně výhodu v tom, že je jedno v jakém jazyce článek je, ale musíte přesně striktně určit, že výsledek má být česky.
Opět si vezmete na pomoc ChatGPT
Vlastně nemusíte umět programovat, protože ChatGPT vám skript vytvoří sama (pro Python) a pomůže i s promptem. Tady ale už to není tak snadné jako poslat, přeložit, získat zpět. Při vytváření skriptů narazíte totiž na výše uvedené zádrhele.
Pokračovat ve čtení: TIP#3168: Jak na ChatGPT API pro souhrn článků na Internetu. Další velmi dobrý příklad včetně kompletního skriptu (odemčeno)Anti-robotická ochrana je řešitelná tak, že posíláte košatý user-agent co odpovídá (třeba) Chrome. Na tom ChatGPT na první dobrou nepřišla, ale když se dozvěděla o chybách 40x, tak jí to došlo.
Do user-agent ale pak přidala accept-encoding pro gzip, takže jsem překvapeně zíral, že místo článku dorazil nějaký binární kód. Vtipné je, že když jí ten kód ukážete, tak řekne, že to je gzip a stačilo accept-encoding vyhodit, zpět se prak vrací text.
To jak z URL dostat článek vyřešila sama hned na samém počátku, pro Python totiž existuje trafilatura a musím říct, že je to neuvěřitelně dobrá pomůcka. Postará se o to, aby ze stažené kompletní HTML stránky do ChatGPT šel opravdu jen text článku.
Vyřešila i zacházení s příliš dlouhými články rozdělením na části (po tuším 6 000 znacích max) a posláním do ChatGPT postupně a pak zpracováním těch více výsledků do jednoho. Zatím to podle všeho funguje docela dobře.
Tady už to chtělo dobré ladění
Při postupné budování skriptu jsem narazil na to, že to různě nedělá co má a řekl si, že by bylo vedle klasického pípní jednou když OK a třikrát když chyba doplnit opravdu “logování” toho co se děje.
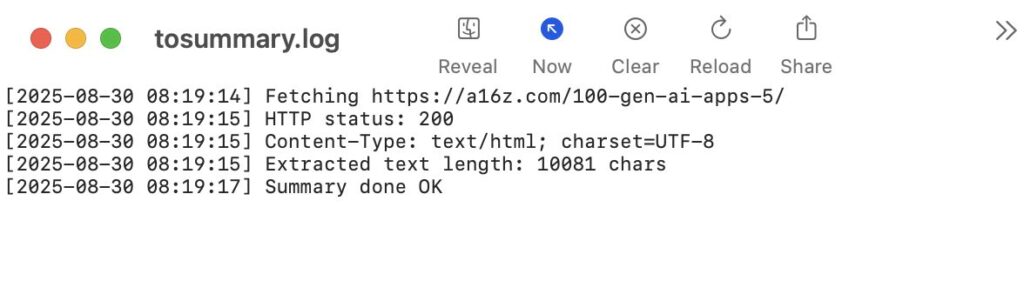
O tohle opět můžete požádat ChatGPT ať na potřebná místa dá logování souboru (uložit tam kde je skript, při spuštění skriptu smazat) a také ať uloží co vlastně bylo staženo do ještě extra souboru (něco co jsem pak ve finální podobě skriptu vypnul.
Chce to precizní prompt
Tady už je dobrý prompt ještě víc důležitý než u překladu – musí totiž vrátit “to podstatné” a musí se to vejít do jednoho odstavce (řekněme dvě, tři věty). Při ladění se navíc ukázalo, že občas svévolně shrne do angličtiny, ačkoliv tam bylo “česky”. Ale i to řeší lépe postavený prompt, tady dokonce česky, protože anglický prompt by opět občas “chyboval”.
TECHMEME_PROMPT = (
"Shrň článek do jednoho krátkého zpravodajského briefu v češtině, ve stylu Techmeme.\n"
"Pravidla:\n"
"- 1–2 věty, celkem maximálně 35 slov.\n"
"- Zaměř se jen na hlavní děj (kdo, co, kdy); bez pozadí a komentářů.\n"
"- Uveď klíčové firmy/osoby a konkrétní čísla, pokud jsou v článku.\n"
"- VŽDY odpověz česky. Nepřidávej nic navíc. Vypiš pouze ten jeden odstavec."
)Tohle je prozatím finální podoba, která docela funguje, byť je možné, že časem bude ještě nějaké drobné dolaďování. Těch “35 slov” je klasicky plus mínus, LLM neumějí dobře počítat, ale tady to nemusí být přesně.
Nezapomenout na teplotu
Teplota/temperature je něco, co v klasické chatgpt (web, aplikace) nemůžete ovlivnit, ale v API ano. Je to parametr, který říká modelu, jak moc má být „kreativní“ nebo „náhodný“ při výběru slov (číslo od nuly do jedné, ale může být i víc).
temperature = 0.0
- model je deterministický: při stejném vstupu vrátí pořád stejný výstup.
- nejvíc se hodí na překlady, sumarizace, faktické odpovědi.
temperature ≈ 0.7 (výchozí u hodně knihoven)
- texty jsou pestřejší, méně „robotické“, ale občas uhne do méně přesného vyjádření.
- hodí se na kreativní psaní, brainstorming, generování nápadů.
temperature > 1.0
- model se chová až moc „divoce“, častěji nesmysly, překlepy, halucinace.
- využitelné jen pro hraní / experimenty.
V sumarizační i překladovém skriptu pak asi nepřekvapi, že je použita nula.
Jaké je tady workflow?
Tenhle další kousek mého arzenálu funguje jako předchozí, tady vstupem je clipboard (v něm je uložená URL), skript zavolá chatgpt a co od ní získá, uloží opět do clipboard.
Stačí jen Ctrl/Cmd+C URL, klávesovou zkratku skriptu a chvíli počkat až pípne, pak Ctrl/Cmd+V na cílové místo. Proti dřívějšímu zadávání do chatu na webu/aplikaci je to fantastická úspora času.
Chce to ale opravdu kontrolovat, jestli to shrnutí nevyrobilo nějaký renonc. A nejen proto, že to jede aktuálně přes gpt-4o-mini – pokud by to nedávalo dobré souhrny, tak je možné zkusit gpt-4o (plné) a případně pokračovat k pětkové.
Původně jsem ten předchozí překladový skript měl na jedné klávesové zkratce a tenhle sumarizační na druhé, ale lze snadno dát na jednu. Ale o tom v tipu Jak na ChatGPT API sloučit překlad a souhrn článku na jednu klávesovou zkratku pomoci Python skriptu, co vlastně není ani tak o ChatGPT API, ale prostě jen o Pythonu a “routeru” co zavolá správný skript podle vstupu.
O týden později, jak vypadá finální skript
Po napsání předchozího textu samozřejmě došlo ještě k nějakým těm změnám:
- Novinky stejně vracely gzip, takže je tam přidán test a “odzipování”)
- Chunking po 6000 znacích je neaktivní, respektive nastavený pro mnohem vyšší hranici. 4o-mini i 4o mají dost velké kontext windows na prakticky všechny články
- A tuším že tady už je i vyřešeno natažení API klíče z .env (a není tedy přímo ve skriptu, tak jak to má být). Mimochodem tady viz RayCast nenačítá proměnné prostředí, jak na ukládání API klíčů? A jak zjistit co Raycast v prostředí má? Co když spouštíte přímo Python?
Ale hlavně, postupně jsem zkoušel různé prompty pro sumarizaci. Takže v následujícím kompletním aktuálním kódu jsou vidět i ty různé varianty. A místo 4o-mini je tam nakonec plná 4o – dává přeci jen lepší výsledky, byť je mírně dražší. Ale testovat se musí (a stejně ji časem nahradí novější model, až ji OpenAI zařízne).
#!/usr/bin/env python3
# @raycast.schemaVersion 1
# @raycast.title Summarize URL to Czech brief
# @raycast.mode silent
# @raycast.packageName AI Tools
# @raycast.icon 📰
import os, sys, re, json, subprocess, urllib.error, traceback, datetime, pathlib
import urllib.request
from dotenv import load_dotenv
load_dotenv()
# --- Log do stejné složky jako skript (při startu vymažeme) ---
LOG_FILE = pathlib.Path(__file__).with_suffix(".log")
LOG_FILE.write_text("", encoding="utf-8")
def log(msg: str):
timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
with open(LOG_FILE, "a", encoding="utf-8") as f:
f.write(f"[{timestamp}] {msg}\n")
# --- KONFIG ---
API_KEY = os.getenv("OPENAI_API_KEY")
# MODEL = "gpt-4o-mini"
MODEL = "gpt-4o"
CHUNK_CHARS = 6000
TECHMEME_PROMPT = (
"Shrň článek do jednoho krátkého zpravodajského briefu v češtině, ve stylu Techmeme.\n"
"Pravidla:\n"
"- 1–2 věty, celkem maximálně 35 slov.\n"
"- Zaměř se jen na hlavní děj (kdo, co, kdy); bez pozadí a komentářů.\n"
"- Uveď klíčové firmy/osoby a konkrétní čísla, pokud jsou v článku.\n"
"- VŽDY odpověz česky. Nepřidávej nic navíc. Vypiš pouze ten jeden odstavec."
)
HEADLINE_PROMPT3 = (
"Převeď článek do jedné až dvou vět, jako kdybys psal titulek na titulní stranu velkého média.\n"
"Pravidla:\n"
"- Maximálně 30 slov.\n"
"- Úderný, chytlavý, snadno srozumitelný pro laiky.\n"
"- Zvýrazni drama, klíčový spor nebo zásadní otázku.\n"
"- Používej aktivní jazyk, ne suché konstatování.\n"
"- Vždy odpověz česky. Vypiš pouze titulek/krátký text, nic navíc."
)
HEADLINE_PROMPT = (
"Převeď článek do jedné až dvou vět, jako titulek na titulní stranu.\n"
"Pravidla:\n"
"- Maximálně 30 slov.\n"
"- Úderný, chytlavý, pro laiky.\n"
"- Zvýrazni drama/kontrast/otázku.\n"
"- Aktivní jazyk, žádné suché konstatování.\n"
"- Nepoužívej vykřičníky ani CAPS; povoleno jen . , : – ? ; max. 1 otazník.\n"
"- Větu ukonči tečkou NEBO otazníkem (nikdy vykřičníkem). Pokud bys použil '!', nahraď jej tečkou.\n"
"- Vždy česky. Vrať pouze titulek."
)
HEADLINE_PROMPT2 = (
"Zapomeň na shrnutí. Jsi novinový titulkář.\n"
"Tvým úkolem je z článku udělat 1–2 věty, které čtenáře okamžitě přitáhnou.\n"
"Pravidla:\n"
"- Délka 22–32 slov.\n"
"- Úderný, chytlavý, může být i řečnická otázka.\n"
"- Zvýrazni velkou sázku, riziko nebo kontrast.\n"
"- Používej silná slovesa a obrazný jazyk (např. 'spaluje', 'vsází všechno', 'honba za svatým grálem').\n"
"- Vyhni se neutrálním frázím typu 'Společnost X, vedená Y…'.\n"
"- Vždy česky. Vrať jen titulek/perex, nic víc."
)
DUAL_PROMPT = (
"Zpracuj článek do dvou verzí:\n\n"
"1) TECHMEME BRIEF:\n"
"- 1–2 věty, max. 35 slov.\n"
"- Suchý, faktický, neutrální zpravodajský styl (Techmeme).\n"
"- Uveď klíčové osoby/firma a čísla.\n\n"
"2) HEADLINE:\n"
"- 1 věta, max. 18 slov.\n"
"- Úderný, chytlavý, expresivní jazyk.\n"
"- Zvýrazni drama nebo kontroverzi (např. 'spaluje miliardy', 'honba za svatým grálem').\n"
"- Může být i řečnická otázka.\n\n"
"Vždy odpověz česky. Vrať obě verze, jasně označené jako 'TECHMEME BRIEF:' a 'HEADLINE:'."
)
ACTIVE_PROMPT = TECHMEME_PROMPT
# --- util ---
def pbpaste() -> str:
return subprocess.check_output("pbpaste", text=True)
def pbcopy(text: str) -> None:
subprocess.run("pbcopy", text=True, input=text, check=True)
def beep(times=1):
subprocess.run(["osascript", "-e", f'beep {times}'])
# --- OpenAI chat/completions přes urllib (rychlé, bez requests) ---
def call_openai_chat(messages, max_tokens=220, temperature=0):
if not API_KEY or API_KEY.startswith("sk-proj-REPLACE_ME"):
log("ERROR: Missing API key")
print("ERROR: Missing OPENAI_API_KEY"); sys.exit(1)
url = "https://api.openai.com/v1/chat/completions"
payload = {
"model": MODEL,
"temperature": temperature,
"max_tokens": max_tokens,
"messages": messages
}
req = urllib.request.Request(
url,
data=json.dumps(payload).encode("utf-8"),
method="POST",
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
},
)
try:
with urllib.request.urlopen(req, timeout=60) as resp:
data = json.loads(resp.read().decode("utf-8"))
return data["choices"][0]["message"]["content"].strip()
except urllib.error.HTTPError as e:
body = e.read().decode("utf-8", errors="ignore")
log(f"HTTP {e.code} ERROR: {body}")
print(f"HTTP {e.code} ERROR:\n{body}")
sys.exit(1)
except Exception as e:
log(f"HTTP ERROR: {e}")
raise
# --- Detailní fetch se status/hlavičkami + UA jako prohlížeč ---
def fetch_with_status(url: str, timeout=20):
import gzip
headers = {
"User-Agent": ("Mozilla/5.0 (Macintosh; Intel Mac OS X 14_7) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/126.0.0.0 Safari/537.36"),
"Accept": ("text/html,application/xhtml+xml,application/xml;q=0.9,"
"image/avif,image/webp,image/apng,*/*;q=0.8"),
"Accept-Language": "en-US,en;q=0.9,cs-CZ;q=0.8,cs;q=0.7",
"Cache-Control": "no-cache",
"Pragma": "no-cache",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
}
req = urllib.request.Request(url, headers=headers)
try:
with urllib.request.urlopen(req, timeout=timeout) as resp:
status = getattr(resp, "status", None)
hdrs = dict(resp.headers)
log(f"HTTP status: {status}")
log(f"Content-Type: {hdrs.get('Content-Type', 'NA')}")
raw = resp.read()
# --- detekce gzip magic bytes ---
if raw.startswith(b"\x1f\x8b"):
try:
raw = gzip.decompress(raw)
log("Applied manual gzip decompression")
except Exception as e:
log(f"Gzip decompress failed: {e}")
# charset z Content-Type (fallback utf-8)
charset = "utf-8"
m = re.search(r"charset=([a-zA-Z0-9_\-]+)", hdrs.get("Content-Type", ""))
if m:
charset = m.group(1).strip()
try:
html = raw.decode(charset, errors="ignore")
except Exception:
html = raw.decode("utf-8", errors="ignore")
return status, hdrs, html
except urllib.error.HTTPError as e:
log(f"HTTPError {e.code}: {e.reason}")
return e.code, {}, None
except urllib.error.URLError as e:
log(f"URLError: {e.reason}")
return None, {}, None
except Exception as e:
log(f"FETCH EXCEPTION: {e}")
return None, {}, None
# --- Fallback kandidáti (AMP/print) ---
def try_fallback_urls(original_url: str):
cands = []
base = original_url[:-1] if original_url.endswith("/") else original_url
cands.extend([
base + "/amp",
base + "/amp/",
base + "?outputType=amp",
base + "?amp",
base + "/print",
base + "/print/",
])
# deduplikace v pořadí
seen, result = set(), []
for u in cands:
if u not in seen:
result.append(u); seen.add(u)
return result
# --- Extrakce článku: fetch -> (případně fallback) -> trafilatura.extract ---
def extract_article_text(url: str) -> str:
try:
import trafilatura
except Exception:
log("ERROR: chybí 'trafilatura'")
print("ERROR: chybí 'trafilatura'. Nainstaluj: python3 -m pip install --user trafilatura")
sys.exit(1)
log(f"Fetching {url}")
status, headers, html = fetch_with_status(url)
if not html or (status in (401, 403)):
log(f"Primary fetch failed or blocked (status={status}); trying fallbacks…")
for fu in try_fallback_urls(url):
log(f"Fallback fetch {fu}")
status, headers, html = fetch_with_status(fu)
if html and (status is None or 200 <= status < 300):
log(f"Fallback OK with {fu}")
break
if not html:
raise RuntimeError(f"Stahování selhalo, status={status}, hlavičky={headers}")
# Extrakce jádra článku
try:
text = trafilatura.extract(
html,
include_comments=False,
include_tables=False,
favor_recall=True,
with_metadata=False
)
except Exception as e:
log(f"trafilatura.extract exception: {type(e).__name__}: {e}")
raise
clean = (text or "").strip()
if len(clean) < 200:
# Logni náhled toho, co se povedlo vyextrahovat (max 500 znaků)
preview = (clean[:500] + ("…" if len(clean) > 500 else "")) if clean else "None"
log(f"Extraction too short ({len(clean)} chars). Preview:\n{preview}")
# Pro hlubší debug ulož i část původního HTML (20 kB) vedle skriptu
debug_html = LOG_FILE.with_suffix(".debug.html")
try:
debug_html.write_text(html[:20000], encoding="utf-8", errors="ignore")
log(f"Saved first 20kB of HTML to {debug_html}")
except Exception as e:
log(f"Failed to write debug HTML: {e}")
raise RuntimeError("Extrakce nenašla dostatek článkového textu.")
# Lehké vyčištění prázdných řádků
clean = re.sub(r'\n{3,}', '\n\n', clean)
log(f"Extracted text length: {len(clean)} chars")
return clean
# --- Shrnutí (s map-reduce pro dlouhé články) ---
def call_brief(article_text: str) -> str:
return call_openai_chat([
{"role": "system", "content": ACTIVE_PROMPT},
{"role": "user", "content": article_text},
])
# Kolik znaků bezpečně pošleme v jednom zátahu (rezerva proti limitu kontextu)
SAFE_SINGLESHOT_CHARS = 80_000 # klidně zvedni na 120_000 podle modelu
def summarize_text_cz(article_text: str) -> str:
# 1) Preferuj one-shot přes celý text (lepší „příběh“ i headline)
if len(article_text) <= SAFE_SINGLESHOT_CHARS:
try:
return call_brief(article_text) # call_brief používá DUAL_PROMPT (nebo tvůj HEADLINE_PROMPT2)
except Exception as e:
# Když by to selhalo kvůli délce, spadneme na map-reduce
if "context" in str(e).lower() or "length" in str(e).lower():
log("One-shot přes limit kontextu, přecházím na chunking…")
else:
raise
# 2) Fallback: map-reduce (rychlé, ale jen fakta v map fázi)
chunks = [article_text[i:i+CHUNK_CHARS] for i in range(0, len(article_text), CHUNK_CHARS)]
log(f"Splitting into {len(chunks)} chunks")
# Důležité: v map fázi vytahuj jen telegrafická fakta, ne mikro-shrnutí (aby finále nebylo sterilní)
chunk_prompt = (
"Z následující části článku vypiš 3–6 telegrafických bodů česky.\n"
"- Pouze klíčové fakty, jména, čísla, citace (jen zásadní).\n"
"- Bez shrnutí, bez stylistiky, bez spekulací.\n"
"- Každý bod na nový řádek, bez odrážek."
)
partials = []
for idx, chunk in enumerate(chunks, 1):
part = call_openai_chat(
[{"role": "system", "content": chunk_prompt}, {"role": "user", "content": chunk}],
max_tokens=160
)
partials.append(part)
log(f"Chunk {idx} summarized ({len(chunk)} chars)")
joined = "\n".join(partials)
# Finální reduce: použij DUAL_PROMPT (nebo tvůj HEADLINE_PROMPT2, pokud chceš jen titulek)
final = call_openai_chat(
[
{"role": "system", "content": DUAL_PROMPT}, # nebo HEADLINE_PROMPT2, podle cíle
{"role": "user", "content": "PODKLADY:\n" + joined},
],
max_tokens=220,
temperature=0.6 # trochu „šťávy“ pro headline
)
return final
# --- Helpery ---
def is_url(s: str) -> bool:
return bool(re.match(r'^https?://', s.strip(), re.I))
# --- Main ---
def main():
clip = pbpaste().strip()
if not is_url(clip):
log("ERROR: Clipboard does not contain URL")
print("ERROR: Ve schránce není URL")
beep(3); sys.exit(1)
try:
article_text = extract_article_text(clip)
except Exception as e:
log("Extract ERROR: " + str(e))
print(f"ERROR: Extrakce textu selhala: {e}")
beep(3); sys.exit(1)
try:
summary = summarize_text_cz(article_text)
except Exception as e:
log("Summarize ERROR: " + str(e))
print(f"ERROR: Shrnutí selhalo: {e}")
beep(3); sys.exit(1)
pbcopy(summary)
print(summary)
log("Summary done OK")
beep(1)
if __name__ == "__main__":
try:
main()
except Exception as e:
log("FATAL ERROR: " + str(e))
log(traceback.format_exc())
print(f"ERROR: {e}")
beep(3)
sys.exit(1)
Další tipy týkající se ChatGPT
-

TIP#2850: Jak pracovat s ChatGPT rozhraním? Základy
Překvapivě často narážím na to, že lidé nevědí jak ChatGPT funguje a jak pracovat s rozhraním, ať už webovým nebo mobilním (je prakticky shodné). Netuší ani základy, takže těmi začneme. A přidám…
-
TIP#2837: Jak funguje ChatGPT search. Základy i pokročile tipy. A proč to není náhrada klasického vyhledávače
ChatGPT má od konce října 2024 novou funkci ChatGPT search. Pokročilejší schopnost integrující vyhledávací nástroje (stále ale Bing) i další zdroje (včetně médií) pro získání aktuálních informací. Včetně velmi dobrého zdrojování. Prozatím…
-

TIP#2834: Advanced Voice Mode na ChatGPT. V čem je jiný než předchozí podoba a k čemu je to dobré?
Do ChatGPT v Evropě dorazilo Advanced Voice Mode. Doposud ho OpenAI klasicky blokovala, protože se dohadovala s EU o dalších podivnostech a šlo to jedině přes VPN. Od 24. října je ale…
-

TIP#2825: Jak funguje paměť (memory) v ChatGPT? Jak zjistit co se o vás naučila?
Od jisté doby má ChatGPT paměť (Memory). Do ní si ukládá věci, které zjistila při vaši konverzaci. Paměť můžete potlačit (v rámci chatu) a můžete se i podívat, co se o vás…
-
TIP#2817: Jak používat dočasný (temporary) chat v ChatGPT a k čemu slouží
ChatGPT je postavená na tom, že můžete vytvářet další a další chaty a poté se k nim případně i kdykoliv vracet a pokračovat v konverzaci. Osobně jich tam mám určitě přes tisícovku…
-

TIP#2808: Jak využít ChatGPT pro návrh témat pro váš web/blog, která ještě nemáte zpracovaná
ChatGPT funguje docela dobře pro navrhování článků na určité téma. Už jsem to probíral v Poradí mi AI jaké další tipy mám psát pro 365tipů? Využití #ChatGPT pro návrh témat v trochu…
-
TIP#2806: Využijte novou “uvažující” ChatGPT o1 pro detailnější zadání pro DALL E 3
OpenAI na počátku září uvedla ChatGPT o1 (v preview podobě) se schopností uvažovat. A je docela zajímavé ji zkusit využit pro lepší návrhy zadání (promptu) pro DALL E 3 v klasické GPT…
-

TIP#2802: Co je to HAARP? A proč si někteří lidé myslí, že slouží USA k manipulaci počasí?
Je to teď aktuální. dezoláti na sociálních sítích tvrdí, že za současné počasí a povodně mohou USA a jakýsi HAARP. Tak jsem se šel zeptat ChatGPT a výjimečně to nedám na JustIT.cz.…
-
TIP#2761: Co umí (neumí) ChatGPT-4o mini vs. plná ChatGPT-4o
V červenci 2024 Open AI vypustili do světa ChatGPT-4o mini. Je tedy dobré vědět co neumí oproti plné a komplexnější ChatGPT-4o. Následjící tabulky pochází přímo od ChatGPT 4o mini. Související příspěvky TIP2567:…
-

TIP#2710: Co všechno je/není možné dělat v neplacené Chat GPT (GPT-4o)?
OpenAI v dubnu 2024 uvolnilo GPT-4o, pokročilejší verzi GPT4, ale hlavně verzi ve které se otevřela řada schopností, které doposud byly pouze v placené GPT Plus. Související příspěvky TIP#3212: Jak využít ChatGPT…
-

TIP#2624: Další šetření času s Image Magick. Vytvoření stínu okolo/pod obrázkem
Dělal jsem to chvíli v Canva, ale je to trochu opruz. Otevřít Canva, nahrát obrázek, vyvolat menu, editace, efekty, stín, stáhnout obrázek. Pak jsem se šel ChatGPT zeptat, jestli nejde Canva nějak…
-

TIP#2621: ChatGPT? Google Bard/Gemini? Microsoft Bing/Copilot? Co vybrat?
Tohle je těžké. Máme tu v zásadě tři hlavní linie generativních umělých inteligencí. ChatGPT od OpenAI, Gemini (dříve Bard) od Google a Copilot (dříve Bing) od Microsoftu. Ta poslední je navíc postavená…
-

TIP#2619: Jak velké množství souborů třídit do složek podle roku a měsíce? A jak v tom pomůže ChatGPT?
Mám v počítači dvě složky, kde každý měsíc přibude spousta souborů a je velmi vhodné ty starší odsouvat někam do archivu, aby ta složka zůstala použitelná. Dlouho jsem to dělal ručně. Prostě…
-

TIP#2577: Jaké jsou nejvíce rozšířené AI mýty?
Další přírůstek do série “Mýty” se týká AI, věci co je aktuálně hodně v kurzu a také tomu odpovídá řada mýtů s tím spojených. Související příspěvky TIP#2396: Jak je to u ChatGPT…
-

TIP2567: Co je to OSINT a pomůže při téhle činnosti AI?
Občas na tuhle zkratku narážím, takže je možná dobré ji přidat k vysvětleným cizím slovíčkům. OSINT je vlastně tak trochu zkratka a znamená „Open Source Intelligence„. Související příspěvky TIP#3037: Jak pracovat s…



